某段时间看了看cve的提交,逛了很久openwall,经过了几次尴尬的邮件交流。发现选对目标很重要~
0x00 为什么写了这么个程序呢
- 发在openwall上面的cve请求邮件太多了,各种类型的应用漏洞都有,并不是所有的都被收录,被收录的也并不是所有类型的都看得懂
- 而且私心觉得这网站的前端很丑,行间距太小了,还带了一种非常html原生的深蓝色字体,作为女生表示看起来很累
- 被cve收录的漏洞请求邮件,间隔几天就会收到来自cve-assign@mitre.org的回复邮件,所以只要爬下回复邮件就知道cve最近收录了哪些漏洞
0x01 使用方法
爬取整年:
openwall.py --year 2016
爬取某年某月:
openwall.py --year 2016 --month 8
完了之后,生成一个html文件:
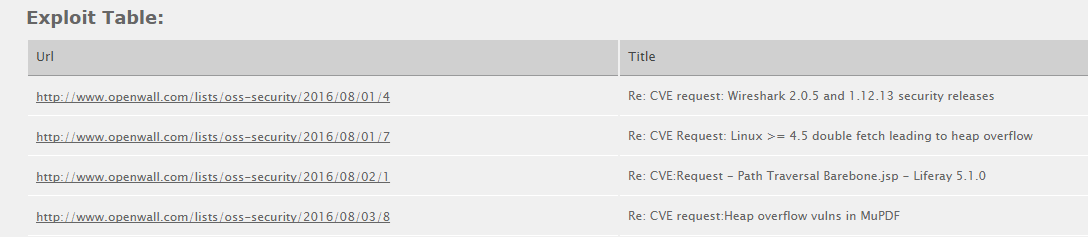
这样,就知道了openwall上最近被收录了哪些漏洞,再自己查关键字,看看有没有可挖的,点进链接该月份通过标题再找到原始邮件,可以看看漏洞详情。过阵子再添加一个获取原始邮件的功能吧~
0x02 细节记录
- 一开始只是想稍微检查一下输入,可以一检查,完全停不下来,于是就花了很大篇幅写了个
check函数,然后并没有什么暖用,但是可以随便调戏程序了 - 爬虫的时候遇到了一个小问题,最开始正则匹配出来一直是错位的,因为这网站的html标签都没有什么特别的属性,邮件标题也是不确定的,改了很久,最后去掉换行符
<li><a href="(\d\d/\d+)">[^\n]*?</a> \(cve-assign@...re.org\),才解决了这个错位 - 最后生成html文件,用了一个非常好用的python库pyh
生成html标题:
page = PyH('Results '+year+' '+month)
添加CSS:
page.addCSS('style.css')
添加JS:
page.addJS('1.js')
添加div:
div_1 = page << div(cl='help',id='table')
‘cl‘是class,’<<‘就是嵌套,在使用’<<‘时,我用的是eclipse,会报错,不知道其他编辑器是不是也这么顽皮,反正不管它
添加表格
table_1 = div_1 << table()
表格中添加列名:
table_1 << tr(th('Url')+th('Title'))
添加表内容,这里用了循环:
for num in xrange(0,len(list_url)):
tr_1 = table_1 << tr(id = 'id_1')
tr_1 << td() << a(list_url[num],href=list_url[num])
tr_1 << td(list_title[num])
最后,保存成文件:
page.printOut(fileName, 'utf-8')

